Kubeflow is a standardized platform for building ML pipelines. It’s an open source ML toolkit, built on top of Kubernetes. Essentially, it translates Data Science work into Kubernetes jobs, and provides a cloud-native, multi-cloud, interface for ML libraries, frameworks, pipelines, and notebooks. This makes it simple to deploy ML pipelines via the containerized approach.
The Kubeflow Pipeline
The Kubeflow Pipeline provides an end-to-end orchestration service, to manage ML pipelines. Furthermore, the idea of abstraction through containerized pipeline components enable Kubeflow Pipelines to be easier to follow, experiment with and debug for potential errors. Finally, these pipelines are easily re-usable, as in no component in a particular order needs to be rebuilt every single time.
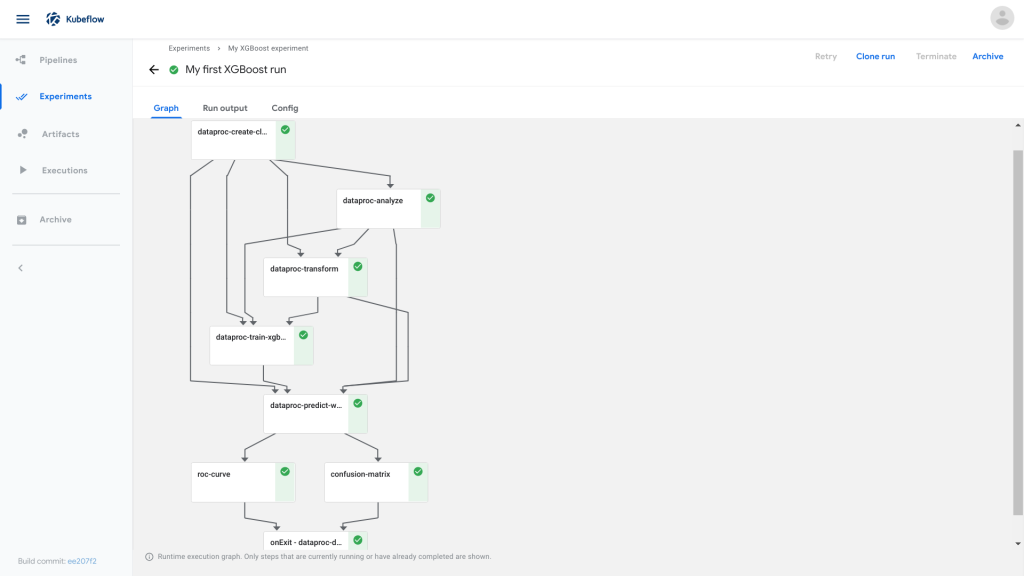
The Kubeflow Pipelines platform consists of a UI to manage the ML pipeline, as well as an SDK where one can modify various components in the pipeline. This can be interfaced using a Python / Notebook script, as the pipeline itself is translated into code. For example:
Placeholder.
For further reading on how the pipelines work in detail, the Kubeflow docs provide an excellent introduction.
Executing a pipeline
The pipeline function must first be created as a decorator function. Next, the run parameters can be specified. Next we specify the input parameters to the pipeline, also called the run parameters. These parameters are specified at run time.
import kfp
# Pipeline decorator
@kfp.dsl.pipeline(
name='Covertype Classifier Training',
description='Covertype Training and Deployment Pipeline'
)
# Pipeline run parameters
def covertype_train(project_id,
region,
source_table_name,
gcs_root,
dataset_id,
evaluation_metric_name,
evaluation_metric_threshold,
model_id,
version_id,
replace_existing_version,
hypertune_settings=HYPERTUNE_SETTINGS,
dataset_location='EU'):Kubeflow Components
For example, a Kubeflow pipeline component can be described in the following way..
Placeholder (YAML file)
Components can be found pre-built in a library: https://github.com/kubeflow/pipelines/tree/master/components
To load the pre-built component, specify:
import kfp
COMPONENT_PATH = ""
URI = COMPONENT_PATH
component_store = kfp.components.ComponentStore(
local_search_paths=None, url_search_prefixes = [URI])
# load example components
bigquery_query_op = component_store.load_component('bigquery/query')
mlengine_train_op = component_store.load_component('mlengine/train')
mlengine_deploy_op = component_store.load_component('mlengine/deploy')